

학습 데이터의 구성

학습에 사용되는 개별 데이터를 샘플이라 한다. = 학습 인스턴스, 학습 예제
학습 데이터는 입력과 출력의 쌍으로 이루어져있고, 새로운 입력에 대한 출력으로 대응관계를 만족시키는 함수 h(x)를 찾는다.
ex) 지역별 주택 가격 예측 문제 :
샘플 1
입력 : 각 지역
출력 : 그 지역의 주택 가격 (서울 강남구, 1,234,000 )
강남과 강북은 비슷하니 부적적할 데이터이다. 입력과 출력의 관계는 명확해야 하며 인구수나 소득 등의 어떤 요소가 영향을 미치는지에 대한 표현이 명확해야 한다. 샘플은 여러 특성(feature, 특징, 자질)들로 구성한다. 즉, 특성들로 목표(target)값을 예측할 수 있도록 학습 데이터를 구성해야 한다.
목표값 = 레이블(label)=클래스(class)
- 샘플은 특성은 벡터(=머신러닝에서는 숫자가 여러 개 모아있는 거) , 전체 샘플 집합은 행렬 (십차원 벡터가 여러 개 있다.)
지도학습 문제의 종류
회귀(regression) : 출력 값이 연속된 구간의 숫자 값인 학습 문제, 학습 데이터를 가장 잘 근사하는 함수를 찾음
ex) 중도 자동차 판매 가격 - 가격에 영향을 미칠만 한 거 > 주행 거리
분류(classification) : 목표값이 연속된 숫자값이 아니고, 단절된 값 / 범주 또는 클래스
- 순서가 없다
- 이산값 h(x) 수학적, 함수일수도, 규칙일수도
ex) 엄마랑 아빠 얼굴 사이에 누가 있을 수 있는가?
특성의 종류
- 수치형
- 텍스트 : 정해진 텍스트 중 하나인 경우 많음
- 대부분 범주형 > 수치형으로 변환해서 사용
원-핫 인코딩(one-hot encoding)
범주형을 원-핫 인코딩으로 표현한다. 범주 개수만큼의 차원으로 구성된 벡터에서 원소 값 하나만 1이고 나머지는 0인 벡터이다. 4개 있으면 4차원 벡터인 것이다. 서로 관계를 배재하기 위해 원-핫 인코딩으로 표현한 것이다. 사과와 과일은 관계가 있으니 굳이 원-핫 인코딩을 사용하지 않는다.
| 스포츠 | → | [1, 0, 0, 0] |
| 정치 | [0, 1, 0, 0] | |
| 문화 | [0, 0, 1, 0] | |
| 연예 | [0, 0, 0, 1] |
범주 개수만큼의 차원으로 구성된 벡터에서 각 범주에 해당하는 원소 값 하나만 1, 나머지는 0으로 구성했다.
특성 1, 특성2이 뭐냐에 따라서 수치값이 달라질 수도 있다. 스케일(=값의 범위)가 많이 다르면 잘 작동하지 않는다. 이런 상황에서는 동일한 범위로 조정하는 특성 스케일링 필요하다.
특성 스케일링 : 정규화 (normalization, min-max 스케일링)
스케일링 하기 전에 x였다면
x → ( x - m ) / ( M - m )
- x : 스케일링 전 특성값
- M : 최대값, m : 최소값
- 0~1 범위로 스케일 조정
특성 1: 10 → (10-5) / (50000-5) = 0.0001
특성2 : 10 → (10-0) / (10-0) = 1
특성 스케일링 : 표준화 (standardization)
x → ( x - 평균 ) / 표준편차
- 평균이 0 분산이 1이 되도록 조정
- 상/하한 값이 없음
- 이상치에 영향을 덜 받음 > 정규화보다 안정적인 방법
학습 데이터의 요건
- 특성 벡터로 표현
- 충분한 양
- 대표성 : 가족의 얼굴 인식, 샘플이 너무 작으면 샘플링 노이즈 , 많은 양을 모으더라도 샘플링 방법이 잘못되면 샘플링 편향
- 학습 데이터를 얼마나 잘 가공하느냐 = 전처리 과정 중요
- 높은 품질 : 이상치 , 누락된 특성값을 어떻게 채워넣을 것이냐 나이가 없는 사람은 없으니
과대적합과 과소적합
과대적합(=과적합)은 학습데이터에 대해 지나치게 잘 학습된 상태이다. 학습 데이터나 오류나 잡음이 있을 수 있는데 너무 잘되어있어도 이것으로 인해 문제가 발생한다. 반면 학습되지 않은 데이터에 대해서는 일반성이 떨어진다. 학습 데이터 양이나 잡음에 비해 모델이 너무 복잡할 때 발생한다.
해결방법 : 모델 단순화, 파라미터 수가 적은 모델 선택, 규제, 학습 데이터의 양 확대, 데이터의 노이즈 축소
과대적합 해결방법 : 규제(Regularization)
- 정칙화, 정규화, 정형화, 조정 어느 것하나 맘에 드는 의미는 없음
- 모델의 자유도를 줄임 , 파라미터의 값에 제약을 둠 / 범위 제한 등등 y=ax+b (<x1>, y1) 기울기를 제한
과소접합(=부적합)은 모델이 너무 단순해서 학습 데이터가 충분히 학습하지 못했을 때 발생한다.
해결방법 : 모델 파라미터가 더 많은 강력한 모델 선택, 학습 데이터가 특성이 하나로 되어있으면 너무 단순함, 학습 데이터의 품질을 높이자, 양질의 질 , 모델 규제 축소 (규제 하이퍼파라미터 감소)
- 특성 선택(10개 다 필요없으면 가장 유용한 것만) / 특성 추출(기존에 있는 걸 결합) / 신규 특성(새로운 데이터 수집)
모델 평가
학습 집합 : 모델 학습용 데이터 집합
테스트 집합 : 평가하기 위한 집합, 일반화 오차 추정 성능평가를 위한 데이터를 미리 보면 안됨(=스누핑)
일반화 오차
편향(bias) : 과정이 잘못되어서 발생하는 오류, 학습데이터가 5차원 모델로 해야 적합했는데 1차로 모델이면 되겠어 하고 직선 형태로 모델링을 해버렸다. 아무리 학습을 잘하더라도 한계 발생함 > 가정자체가 잘못되어버렸다 / 과소적합되기 쉬움
분산 : 너무 민감해서 발생하는 오류, 자유도가 높은 모델에서 발생 , 과대접합되기 쉬움
줄일 수 없는 오차 : 데이터 자체에 있는 잡음때문에 발생하는 오차, 데이터 정제로 오차를 줄일 수 있다.
편향/분산 트레이드 오프 : 모델 복잡도가 커지면 분산 커지고 편향은 낮아짐
모델 선택 및 튜닝
예를 들어 선형 모델과 다항 모델이 있다. 어떤 모델을 선택해야 하는가? 모델 선택에 있어서는 같은 테스트 집합으로 비교 후 성능이 더 높은 걸 선택한다.
하이퍼파라미터(hyperparameter)
하이퍼파라미터는 모델의 파라미터가 아니라 학습 알고리즘의 파라미터이다. 학습 알고리즘으로부터 영향을 받지 않고, 학습 전에 미리 지정되어 학습하는 동안은 상수이다. 머신러닝 진행하는 사람이 적절하게 넘겨줄수도 있지만, 값을 무작정 정하기 보다는 데이터에 의해서 결정되도록 해주는 것을 권한다.
홀드아웃 검증
- 별도의 검증 집합을 사용하여 모델 선택(하이퍼파라미터 결정)
- 검증 집합 : 여러 후보 모델 중 좋은 거 , 학습 집합의 일부를 떼어내어 구성, 개발 집합
홀드아웃 검증 - 학습 및 평가 절차
학습 : 줄어든 학습 집합(검증 집합 제외)으로 다양한 하이퍼파라미터를 사용한 여러 모델 학습
검증(최적 모델 선택) : 검증 집합에서 가장 높은 성능을 보이는 모델 선택
최종 모델 생성 : 검증 집합을 포함한 모든 학습 집합으로 선택된 모델 학습
평가 : 최종 모델을 테스트 집합에서 평가하여 일반화 오차 추정
교차 검증
데이터가 부족한 상황에서 가능한 많은 데이터를 학습에 사용하면서 성능 평가하는 방법이다.
- k 겹 교차 검증
- 총 400개가 있어 4등분 해 100개씩, 반복적으로 학습과 검증을 하나를 검증 나머지는 트레이닝 용으로 사용
- 각 등분을 한번씩 검증 집합으로 사용하여 K 번 성능평가를 하고 평균값으로 성능 추정
- but, 훈련시간 = 검증 세트의 개수 비례
이진 분류 모델 성능 평가 : 혼동 행령(Confusion Matrix)
- 분류기 성능을 평가하는 더 좋은 방법
- 행 = 실제 클래스 / 열 = 예측 클래스
| 실제\예측값 | 음성 | 양성 |
| 음성 | TN | (오류) FP |
| 양성 | (오류) FN | TP |
정확률과 재현율
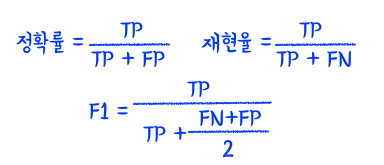
정확률 (=정밀도) : 양성 예측의 정확도 정확률을 높이고 싶으면 FP 값을 줄인다. 전체 개수를 줄이면 됨.
재현율, 민감도 , 진양성 비율 : 분류기가 정확하게 감지한 양성 샘플의 비율, 검색엔진에도 사용, 재현율을 높이려면tp를 높여, 그냥 다 positive로 해버려, 그러나 정확률은 낮아짐.
*서로 상쇄관계 둘 다 높으면 좋은 모델
Accuracy(정확도)
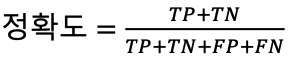
- 전체 샘플 중 올바르게 예측한 샘플 비율
'사망년 > 머신러닝' 카테고리의 다른 글
| 비지도 학습 (1) | 2023.12.07 |
|---|---|
| 분류 (1) | 2023.12.07 |
| 서울시 공공자전거 수요 예측을 위한 데이터 수집 및 통합 과정 (2) | 2023.12.02 |
| 04_회귀(Regression) (0) | 2023.09.22 |
| 01_머신러닝 개요 (0) | 2023.08.31 |